In 2022, the Special Education Research Accelerator received funding from the National Science Foundation’s EDU Core Research (ECR) program to launch Crowdsource Science, a nationally representative observation study focused on investigating science education for fourth and fifth graders with learning disabilities. This comprehensive study involves collecting survey data, audio recordings, permanent products, classroom observations, and interviews. By analyzing instructional practices and student engagement, the project aims to illuminate what science instruction looks like for students with learning disabilities, addressing the documented achievement gap and providing insights to better support these learners.
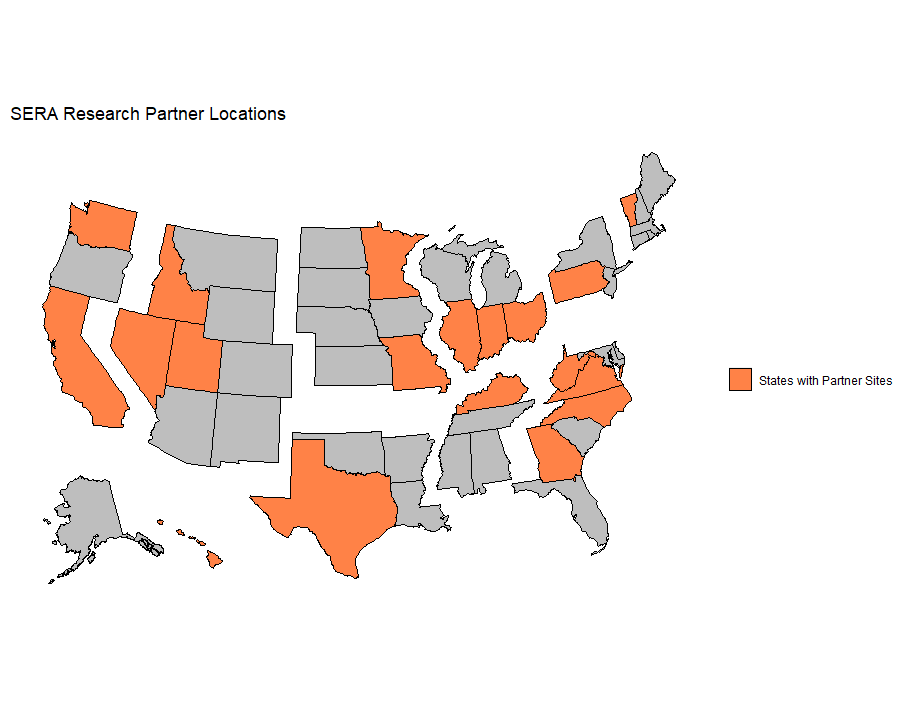
The first year of data collection, during the 2023-2024 school year, has laid a strong foundation for the project. We partnered with 18 SERA Research Partners across the country to collect data from 29 teachers in 19 schools across 14 states. These teachers provided invaluable insights into the type of science instruction received by fourth and fifth grade students with learning disabilities. This initial phase has been crucial in establishing a comprehensive understanding, and we eagerly anticipate a second year of data collection to deepen our insights and continue advancing our goals.
In this project, we developed and piloted a platform for crowdsourcing research in special education, enabling numerous researchers to collect data in schools throughout the country. Crowdsourcing has the potential to increase the number and diversity of students participating in studies, making research findings more relevant to educators in various settings nationwide. However, until now, no platform existed to facilitate crowdsourced special education research.
Our crowdsourcing platform, the Special Education Research Accelerator (SERA), is hosted on the SERA website (https://edresearchaccelerator.org/). It provides resources to support research partners nationwide in implementing study procedures consistently, such as video trainings, detailed data collection protocols, and access to the SERA Data Portal. We have also recruited a network of over 350 doctoral-level researchers interested in participating in crowdsourced research in special education, some of whom took part in this pilot study.
To pilot our crowdsourcing platform and process, we designed an experiment to test the effects of prompting elementary students with high-incidence disabilities to generate explanations on remembering animal facts. In a previous study, Scruggs and colleagues (1994) found that students who generated their own explanations had significantly greater immediate and delayed recall (after one week) of animal facts compared to a control group that merely repeated the facts. This study involved 36 fourth- and fifth-grade students with high-incidence disabilities in the Ohio River Valley. We replicated this study to determine if we would observe the same effects with a different group of students from across the country.
Example Animal Facts and Explanations
Fact
Explanation
The emperor penguin carries its eggs on top of its feet.
The emperor penguin carries its eggs on top of its feet because the emperor penguin lives in an icy world and has to keep its eggs off the ice to keep them warm.
Some frogs lay eggs that sink in water.
Some frogs lay eggs that sink in water because eggs that have sunk to the bottom of the water are harder for other animals to find and eat.
The aardvark can completely close its nostrils.
The aardvark can completely close its nostrils because the aardvark digs in the dirt for food and needs to keep dust, dirt, and bugs from getting in its nose
Due to the pandemic, we redesigned the pilot study to allow researchers to implement procedures and collect data online. The pilot ultimately involved seven research teams from Temple University, Texas Christian University, University of Missouri, University North Carolina-Wilmington, University of Louisville, University of Virginia, and Washington State University-Vancouver. These teams conducted the study with 31 third- and fourth-grade students with high-incidence disabilities from across the country.
In contrast to Scruggs and colleagues’ findings, our study found that prompting students to generate explanations for animal facts did not result in better immediate or delayed recall (after one week) compared to the control group, which merely repeated the facts. This discrepancy between our findings and the previous study’s results may be due to the online delivery of the intervention and/or differences in the student samples. Further research is needed to determine under what conditions and for which students generating explanations of science facts improves recall.
Although we did not find that generating explanations for animal facts helped students recall the facts better than simply repeating them, conducting the pilot study allowed us to demonstrate the feasibility of crowdsourcing field-based research with students with disabilities across multiple research teams. Additionally, it provided valuable information for refining and expanding SERA.
We want to thank our participating SERA research partners, schools, teachers, and students for their invaluable participation in this initiative. Their contributions are fundamental to establishing a robust evidence base aimed at improving students’ future outcomes.
The original funding for developing and piloting the Special Education Research Accelerator (SERA) was provided by a grant from the Institute for Education Sciences (IES). Though the pandemic presented many obstacles, the project resulted in, among other accomplishments, the SERA website, which serves as a hub for crowdsourced research studies conducted by SERA; a network of approximately 370 SERA partners (special education researchers interested in conducting crowdsourced research) throughout the US; and a pilot RCT replication examining the effects of elaborative interrogation on the retention of science facts among elementary students with high-incidence disabilities across eight SERA research partners (we are currently writing up the results of that study, check our blog for a forthcoming summary). We learned a lot working with our partners in this project. One thing that stood out to us was that although we had developed infrastructure and procedures for crowdsourcing research studies across many researchers and sites, a similar process for crowdsourcing the planning of research does not yet exist. Therefore, we proposed (and were fortunate to receive funding for) an IES grant, which we’re referring to as SERA2, to expand SERA by developing and piloting procedures and supports for crowdsourcing the development of lines of inquiry to systematically investigate effect heterogeneity for the purpose of estimating generalizability boundaries.
Generalization requires understanding sources of variation that may amplify or dampen intervention effects (Stuart et al., 2011; Tipton, 2012; Tipton & Olsen, 2018). Cronbach identified four classes of contextual variables that could potentially affect the size of intervention effects. They include variations in unit (or participants), treatment (or versions of the intervention), outcome, and/or setting (UTOS) characteristics. For example, the effects of an intervention may vary for students with learning disabilities compared to students with autism, when implemented in small groups versus individually, when delivered with reading specialist versus a paraprofessional, and/or the combination of these characteristics combined.
To fully inform policy and practice about the effectiveness of programs and interventions, researchers should examine treatment effect heterogeneity across key learner populations, treatment variations, outcomes, and settings. It seems to us that this is just the type of information policymakers and practitioners want to know: Does this intervention work for students with autism? Does it work when implemented in small groups? However, researchers seldom design series of conceptual replication studies that systematically examine effect heterogeneity across key moderator variables. And if one researcher or research team were to design such a series of studies, it would take them many years if not decades to conduct studies examining all the possible combinations of key moderator variables to fully examine effect heterogeneity.
In the first stage of SERA2, we worked with a Consensus Panel to identify key moderator variables across which to examine effect heterogeneity for repeated reading, a commonly used intervention to improve reading performance for students with learning disabilities. The Consensus Panel included six experts in repeated reading and/or reading instruction for culturally and linguistically students with learning disabilities. Panel members attended a two-day meeting at the University of Virginia to develop an initial list of key moderator variables for repeated reading. We will then use this list of hypothesize moderators to design a series of conceptual replication studies to investigate systematic sources of effect heterogeneity for repeated for students with learning disabilities. Drs. Scott Ardoin (University of Georgia), Young-Suk Kim (University of California-Irvine), Endia Lindo (Texas Christian University), Michael Solis (University of California-Riverside), Elizabeth Stevens (University of Kansas), and Jade Wexler (University of Maryland) participated in a Nominal Group Technique to develop initial consensus on the most important moderator variables moderator variables. Nominal Group Techniques involve four stages: idea generation, nomination, discussion, and ranking. Day 1 ended with experts ranking the importance of nominated moderator variables in each of the UTOS categories. After sharing the results of the rankings, our group of experts re-nominated, re-discussed, and re-ranked key moderator variables for repeated reading in Day 2. The highest ranked variables in each UTOS category at the end of Day 2 were:
Units: students with learning disabilities with low vs. high decoding skills
Treatments: (a) difficulty of passages and (b) modelling skilled reading of passages (tie)
Observations: type of oral reading fluency measure
Settings: individual vs. group administration
Using these variables, co-PI Dr. Vivian Wong and Project Consultant Dr. Peter Steiner (University of Maryland) are developing a series of conceptual replication studies (an integrated replication design) to systematically investigate the effects of repeated reading across the many combinations of the levels of these variables. We will then be conducting focus groups with practitioners with experience teaching repeated reading and a broader group of researchers with expertise in reading intervention to garner feedback on the selected moderator variables and the draft integrated replication design. In the second stage of the project, we will involve SERA research partners to crowdsource piloting of selected studies in the integrated replication.
We will be providing progress updates as here as the project progresses and are excited about the potential of identifying key moderator variables for other commonly used interventions in special education, with the ultimate goal informing policy and practice by crowdsourcing studies across many research teams to systematically examine effect heterogeneity in a short time frame.
Along with seven research-partner teams across the country, we finished collecting data for the SERA Pilot Study: Science Instruction for Students with Disabilities in 2022. As the SERA Team finishes analyzing outcome data (check back soon for a summary of procedures and findings), we conducted internal reviews with our team and participating research partners to elicit their feedback on the implementation of this crowdsourced research study. Without these research partnerships, our efforts to democratize and accelerate the pace of research through crowdsourcing special education research would not be possible. We value these partnerships and are incredibly grateful for all our SERA Research Partners who participated in the pilot study.
One of the seven research teams we worked with throughout the SERA Pilot Study was the team at University of North Carolina Wilmington (UNCW). The UNCW research team included Dr. Amelia Moody, Dr. James Stocker, Dr. Sharon Richter, and Racheal Gliniak (graduate research assistant).
The following post was written by Drs. Amelia Moody and James Stocker to summarize their experience as SERA Research Partners:
Crowdsourcing in special education research offers opportunities to determine the types of evidence-based interventions that function most effectively and efficiently across diverse populations of students. The Special Education Research Accelerator (SERA) at the University of Virginia welcomes a diverse array of researchers to participate in large-scale replication research. At the University of North Carolina Wilmington, we had the opportunity to engage as a research partner in a crowdsourcing pilot study on science facts. We piloted the study in both rural and urban schools, with the majority of schools located in high-poverty locations.
We received training materials and videos to guide us through each step of data collection. The SERA team provided extraordinary support, and we found them easily accessible to answer questions throughout the study. We enjoyed problem-solving together to meet the unique needs of our students located in high-poverty areas. In one instance, an urban school had a number of issues related to sharing and collecting information through digital means as well as internet accessibility. Our team identified the barriers and generated solutions alongside the SERA team. We quickly converted to paper format and successfully recruited participants through flyers in backpacks. Also, data collection for each participant occurred via a school liaison versus web-based questionnaires for parents/guardians that had outdated contact information. We quickly realized that when developing large and diverse participant samples, it is critical to have multiple options to meet the needs of each population of students.
We discovered that the SERA team at the University of Virginia accepted and valued our feedback on the pandemic-modified intervention procedure. We delivered the intervention via zoom and provided information back to the SERA team to improve the application and fidelity of the protocol. Overall, we collected a significant amount of data across multiple sites alongside other SERA partners across the country. Our participation allowed SERA to gain data from a more diverse population of participants. The goal of the project was to answer critical questions about how to improve outcomes for children with disabilities. The crowdsourcing process was effective and efficient in meeting this goal.
Click here to view a full list of SERA Research Partners. If you are interested in becoming a SERA Research Partner and learning more about our upcoming studies, please submit a message through our Contact Form and a member of the SERA Team will reach out to you!
Since the start of the war on poverty in the 1960s, social scientists have developed and refined experimental and quasi-experimental methods for evaluating and understanding the way public policies affect people’s lives. The overarching mission of many social scientists is to understand “what works” in social policy for reducing inequality, improving educational outcomes, and mitigating harms of early life disadvantage. This is a laudable goal. However, mounting evidence suggests that the results from many studies are fragile and hard to replicate. The so-called “replication crisis” has important implications for evidence-based analysis of social programs and policies. At the same time, there is intense debate about what constitutes a successful replication and why certain types of replication rates are so low. A crucial set of questions for evidence-based policy research involve questions about external validity and replicability. We need to understand the contexts and conditions under which interventions produce similar outcomes.
To address these concerns, Peter Steiner and I presented a new framework that provides a clear definition of replication, and highlights the conditions under which results are likely to replicate (Wong & Steiner, 2018; Steiner, Wong, & Anglin, 2019). This work introduces the Causal Replication Framework (CRF), which defines replication as a research design that tests whether two or more studies produce the same causal effect within the limits of sampling error. The CRF formalizes the conditions under which replication success can be expected. The core of the replication framework is based on potential outcomes notation (Rubin, 1974), which has the advantage of identifying clear causal estimands of interest and demonstrating research design assumptions needed for the direct replication of results. Here, a causal estimand is defined as the causal effect of a well-defined treatment-control contrast of a clear target population. In this blog post, I discuss key assumptions needed for direct replication of results, describe how the CRF may be used for planning systematic replication studies, and how the CRF is informing out development of a “crowdsourcing platform” for SERA.
Under the CRF, five assumptions are required for the direct replication of results across multiple replication studies. These assumptions may be understood broadly as replication design requirements (R1-R2 in Table 1), and individual study design requirements (A1-A3 in Table 1). Replication design assumptions include treatment and outcome stability (R1) and equivalence in causal estimands (R2). Combined, these two assumptions ensure that the same causal estimand for a well-defined treatment and target population is produced across all studies. Individual study design assumptions include unbiased identification of causal estimands (A1), unbiased estimation of causal estimands (A2), and correct reporting of estimands, estimators, and estimates (A3). These assumptions ensure that a valid research design is used for identifying effects, unbiased analysis approaches are used for estimating effects, and that effects are correctly reported – standard assumptions in most individual causal studies. Replication failure occurs when one or more of the replications and/or individual study design assumptions are not met. Table 1 summarizes the assumptions needed for the direct replication of results.
Table 1. Design Assumptions for Replication of Effects (Steiner & Wong, in press; Wong & Steiner, 2018)
Design Assumptions
For Study 1
… Through Study k
Replication design assumptions (R1-R2)
R1. Treatment and outcome stability R2. Equivalence in causal estimand
R1. Treatment and outcome stability R2. Equivalence and causal estimand
Individual study design assumptions (A1-A3)
A1. Unbiased identification of effects A2. Unbiased estimation of effects A3. Correct reporting of estimators, estimands, and estimates
A1. Unbiased identification of effects A2. Unbiased estimation of effects A3. Correct reporting of estimators, estimands, and estimates
Deriving Research Designs for Systematic Replication Studies
A key advantage of the CRF is that it is straight-forward to derive research designs for replication to identify sources of effect heterogeneity. For example, direct replications examine whether two or more studies with the same well-defined causal estimand yields the same effect (akin to the definition of verification tests in Clemens, 2017). To implement this type of design, the researcher may introduce potential violations to any individual study design assumptions (A1-A3), such as using different research design (A1) or estimation (A2) approaches for producing effects, or asking an independent investigator to reproduce the effect using the same data and code (A3). Design-replications (Lalonde, 1986) and reanalysis or reproducibility studies (Chang & Li, 2015) are examples of direct replication approaches. Conceptual replications examine whether 2+ studies with potentially different causal estimands yield the same effect (akin to definition of robustness tests in Clemens, 2017). Here, the researcher may introduce systematic violations to replication assumptions (R1-R2), such as multi-site designs where there are systematic differences in participant and setting characteristics across sites (R2), and multi-arm treatment designs when different dosage levels of an intervention is assigned (R1). The framework demonstrates that while the assumptions for direct replication of results are stringent, researchers often have multiple research design options for evaluating the replicability of effects and identifying sources of effect variation. However, until recently, these approaches have not been recognized as systematic replication designs. Wong, Anglin, and Steiner (2021) describe research designs for conceptual replication studies, and methods for assessing the extent to which replication assumptions are met in field settings.
Using Systematic Replication Designs for Understanding Effect Heterogeneity
Wong and Steiner (2018) show that replication failure is not inherently “bad” for science – as long as the source of the replication failure can be identified. Prospective research designs or research design features may be used to address replication assumptions in field settings. The multi-arm treatment design, where units are randomly assigned units to different treatment dosages, is one example of this approach. A switching replication design, where two or more groups are randomly assigned to receive treatment at different time intervals in an alternating sequence is another example (Shadish, Cook, & Campbell, 2002). Here, the timing and context under which the intervention is delivered vary, but all other study features (including composition of sample participants) remain the same across both intervention intervals. In systematic replication studies, a researcher introduces planned variation by relaxing one or more replication assumption while trying to meet all others. If replication failure is observed—and all other assumptions are met—then the researcher may infer that the assumption was violated and resulted in treatment effect heterogeneity.
Using the CRF to Plan Crowdsourced Systematic Replication Studies
In crowdsourcing efforts such as SERA, teams of independent investigators collaborate to conduct a series of conceptual replication studies using the same study protocols. These are conceptual replication studies because although sites may have the same participant eligibility criteria, the characteristics of recruited sample members, the context under which the intervention is delivered, and the settings under which the study is conducted will likely vary across independent research teams. A key challenge in all conceptual replication studies – including those in SERA – is identifying why replication failure occurred when multiple design assumptions may have been violated simultaneously.
To address these concerns, SERA is developing infrastructure and methodological supports for evaluating the replicability of effects, and for identifying sources of effect heterogeneity when replication failure is observed. These tools are based on the Causal Replication Framework and focus on three inter-related strands of work. First, we are working with the UVA School of Data Science (Brian Wright) to create a crowdsourcing platform that will ensure transparency and openness in our methods, procedures, and data. A crowdsourcing platform that allows for efficient and multi-modal data collection is critical for helping us evaluate the extent to which replication assumptions are met in field settings. We are also working on data science methods for assessing the fidelity and replicability of treatment conditions across sites in ways that are valid, efficient, and scalable. This will provide information about the extent to which the “treatment stability” assumption (R2 in Table 1) is met in field settings. Finally, we are examining statistical approaches for evaluating the replicability of effects, especially when there is evidence of effect heterogeneity. Over the next year, we look forward to sharing results from these efforts and what our team has learned about the “science” of conducting replication studies in field settings.
Replication Quantitative Methods Team includes Vivian C Wong (UVA), Peter M Steiner (Maryland), Brian Wright (UVA SDS), Anandita Krishnamachari (Research Scientist), and Christina Taylor (Replication Specialist).
Vivian C. Wong, Ph.D.
Research Faculty
Vivian C. Wong, Ph.D., is an Associate Professor in Research, Statistics, and Evaluation at UVA. Dr. Wong’s expertise is in improving the design, implementation, and analysis of experimental and quasi-experimental approaches. Her scholarship has focused recently on the design and analysis of replication research. Dr. Wong has authored numerous articles on research methodology in journals such as Journal of Educational and Behavioral Statistics, Journal of Policy Analysis and Management, and Psychological Methods. Wong is primarily responsible for developing the methodological infrastructure and supports for SERA, assisting with methodological components of the pilot study, and conducting exploratory analyses of SERA.
Educators strive to improve and maximize the learning outcomes of their students by applying effective instructional practices. Although no instructional approach is universally effective, some teaching practices are more effective than others. Therefore, it is important to reliably identify and prioritize the most effective instructional practices for populations of learners. Rigorous experimental research is generally agreed to be the most reliable approach for identifying “what works” in education. However, it is important to recognize that scientific research has important limitations and does not always generate valid findings.
In large-scale replication projects in psychology and other fields, researchers often failed to replicate the findings of previously conducted studies (e.g., Klein et al., 2018; Open Science Collaboration, 2015), casting doubt on the validity of research findings. Researchers, including those in education, have also reported using a variety of questionable research practices such as p-hacking (exploring different ways to analyze data until desired results are obtained), selective-outcomes reporting (only reporting analysis with desired results), and hypothesizing after results are known (HARKing; e.g., Fraser et al., 2018; John et al., 2012; Makel et al., 2019), all of which increase the likelihood of false positive findings (Simmons et al., 2011). Moreover, research studies in education often involve relatively small and underpowered samples that do not adequately represent the population being studied, which further threatens the validity of study findings. Finally, most published research lies behind a paywall, inaccessible to many practitioners and policymakers (Piwowar et al., 2018), which reduces the potential application and impact of research. Open science and crowdsourcing are two related developments in research that aim to address these issues and improve the validity and impact of research.
Open science is an umbrella term that includes a variety of practices aiming to open and make transparent all aspects of research with the goal of increasing its validity and impact (Cook et al., 2018). For example, preregistration involves making one’s research plans transparent before conducting a study in order to discourage questionable research practices such as p-hacking and HARKing by making them easily discoverable. Data sharing is another key open-science practice, which allows the research community to verify analyses reported in an article, as well as analyze data sets in other ways to examine the robustness of reported findings, thereby serving as a protection against p-hacking. Materials sharing involves openly sharing materials used in a study (e.g., intervention protocols, intervention checklists) to enable other researchers to replicate the study as faithfully as possible. Finally, open access publishing and preprints provide free access to research to anyone with internet access, thereby democratizing the benefits and impact of scientific research beyond those with institutional subscriptions to the publishers of academic journals.
Crowdsourcing in research involves large-scale collaboration of various elements of the research process and can take many forms (Makel et al., 2019). For example, multiple research teams might conduct independent studies examining the same issues, as the Open Science Collaboration (2015) did when they conducted 100 replication studies to examine reproducibility of findings in psychology. Crowdsourcing in research has also occurred by multiple analysts analyzing the same data set to answer the same research question in order to examine the effects of different analytic decisions on study outcomes (Silberzahn et al., 2018). The most frequent application of crowdsourcing in research, which we have adopted in the Special Education Research Accelerator, is to involve many research teams in the collection of data, thereby increasing the size and diversity of the study sample – which serves to improve the study’s power and external validity. For example, Jones et al. (2018) involves > 200 researchers collecting data from > 11,000 participants in 41 countries to evaluate facial perceptions. Regardless of how it is employed, “crowdsourcing flips research planning from ‘what is the best we can do with the resources we have to investigate our question?’ to ‘what is the best way to investigate our question, so that we can decide what resources to recruit?” (Uhlmann et al., 2019, p. 417).
Although open science and crowdsourcing are independent constructs (i.e., research that is open is not necessarily crowdsourced, and crowdsourced studies are not necessarily open), the two approaches are closely aligned and complementary. The ultimate goal of both open science and crowdsourcing is to improve the validity and impact of research. Although using different means to achieve this goal, crowdsourcing facilitates making research open, and open science facilitates crowdsourcing. For example, in a crowdsourced study in which data are collected by many research teams, study procedures have to be determined and disseminated to collaborating researchers before the study is begun. Because study procedures are determined and documented prior to conducting the study, they can readily be posted as a preregistration. Additionally, if data are being collected across many researchers in a crowdsourced study, the project will need a clear data-management plan to enable data to be collected and entered reliably across researchers. Such well-organized data-management plans that include metadata not only facilitate the integration of data across researchers on the project, but also make data more readily usable by other researchers when shared and reduce the burden of creating supporting metadata when sharing. Moreover, because data are collected across many different researchers in many crowdsourced studies, individual researchers may be less likely to feel that they “own” the data and therefore may feel less reluctant to share them. Similarly, materials used in crowdsourced studies must have been developed and shared with the many researchers collecting data, so – like data – materials from crowdsourced research are ready to be uploaded and shared. Most broadly, crowdsourcing and open science share an ethos of collaboration and sharing for the betterment of science, and we conjecture that most researchers involved in crowdsourced studies will want to make their research as open as possible. As such, we look forward to making our crowdsourced research through the Special Education Research Accelerator as open as possible.
Bryan G. Cook, Ph.D.
Principal Investigator
Bryan G. Cook, Ph.D., is a Professor in Special Education at UVA with expertise in standards for conducting high-quality intervention research in special education, replication research in special education, and open science. He co-directs, with Dr. Therrien, the Consortium for the Advancement of Special Education Research (CASPER) and is an ambassador for the Center for Open Science. He is Past President of CEC’s Division for Research, chaired the working group that developed CEC’s (2014) Standards for Evidence-Based Practices in Special Education, coedits Advances in Learning and Behavioral Disabilities, and is coauthor of textbooks on special education research and evidence-based practices in special education. Cook plays an integral role in developing infrastructure and supports for SERA, conducting the pilot study, and assessing the usability and feasibility of using SERA to conduct future replication pilot studies.
In crowdsourced
research, resources are combined across researchers to conduct studies that
could not be accomplished on their own.
“Crowdsourcing
flips research planning from ‘what is the best we can do with the resources we
have to investigate our question,’ to ‘what is the best way to investigate our
question, so that we can decide what resources to recruit.”
(Uhlmann
et al., 2019, p. 7).
Crowdsourcing
research is new to special education research, but in other fields, it has been
around for decades. Many aspects of research can be crowdsourced, such as deciding
what ideas to research, analyzing data, and conducting peer review (Uhlmann et
al., 2019). The most common use of crowdsourcing is regarding data collection,
in which many researchers collect data, resulting in much larger and diverse
samples of study participants. Examples of crowdsourced data collection outside
of special education include:
Citizen
data collectors: Fields such as astronomy and geology
utilize volunteers to collect data that researchers would never be able to
collect on their own. Many of these projects and opportunities to become data
collectors are compiled on the federal government citizen science website.
Conducting
crowdsourced research, especially involving crowdsourcing data collection, in
special education has many potential uses such as:
Implementing large scale observational
studies so we can better understand how students with disabilities are provided
services across the country
Validating evidence-based practices using nationally
representative student samples
Enabling adequately powered group studies
with low-incidence populations to be conducted
Dramatically increasing the number of direct
and conceptual replications so we can efficiently determine what interventions
work for who, under what conditions (Coyne
et al., 2016).
Ultimately, we
envision crowdsourcing will democratize the research enterprise by enabling
more and diverse researchers to be involved in large-scale research studies involving
large and diverse participant samples that ask and answer critical research questions
aimed at improving services for children with disabilities. By facilitating
crowdsourcing of data collection across many researchers, we hope the Special
Education Research Accelerator (SERA) will play a core role in democratizing
the research enterprise in our chosen field — special education.
William J. Therrien, Ph.D., BCBA
Co-Principal Investigator
William J. Therrien, Ph.D., BCBA, is a Professor in Special Education at UVA. He is an expert in designing and evaluating academic programming for students with disabilities, particularly in science and reading. Along with co-directing CASPER, Dr. Therrien co-edits Exceptional Children, the flagship journal in special education, and is Research in Practice Director for UVA’s Supporting Transformative Autism Research (STAR) initiative. Therrien assists Cook with developing infrastructure and supports for SERA, conducting the pilot study and assessing the usability and feasibility of using SERA to conduct future replication pilot studies.
Bryan G. Cook,
William J. Therrien, Vivian C. Wong, Christina Taylor
We are pleased to welcome you to the Special Education
Research Accelerator (SERA). SERA is a platform for crowdsourcing data
collection in special education research across multiple research teams. When
we read about the Psychological Research
Accelerator, which crowdsources data collection for massive studies in the
field of psychology conducted throughout the world, we began to think about the
potential benefits of crowdsourcing in special education research. In essence,
instead of a single research team conducting a study, crowdsourcing of data
collection involves a network of research teams collecting data. Crowdsourcing
allows researchers to flip “research planning from ‘what is the best we can do
with the resources we have to investigate our question,’ to ‘what is the best
way to investigate our question, so that we can decide what resources to
recruit’” (Uhlmann et al.,
2019, p. 713).
Given that there are relatively few students with
disabilities, especially low-incidence disabilities, in schools, it is often
difficult for special education researchers to obtain large, representative
samples for their studies. Moreover, given limited grant funding, relatively
few researchers in the field have the resources to conduct studies with large,
representative samples on their own. Crowdsourcing data collection across many
research teams seemed to us to be well-suited to address these and other
challenges faced in special education research.
However, implementing crowdsourcing in special education
research presents many challenges. Can interventions be conducted with fidelity
across many different research teams? How will data be managed? How will
implementation fidelity be measured? How will IRB issues be handled across
multiple institutions? Fortunately, the National Center for Special Education
Research (NCSER) funded an unsolicited grant
for us to develop and pilot a platform for crowdsourcing research in special
education research (i.e., SERA) to examine these and other issues. By involving
many different research teams in data collection of studies, SERA can generate
large and representative study sample, involve diverse sets of researchers, and
examine whether and how study findings vary across researchers and researcher
sites, in ways that studies conducted by a single research team could not.
This website has two primary functions: (a) a public-facing
site to provide information and resources related to SERA and crowdsourcing
research in special education, and (b) a hub for research partners to access
resources and interact with SERA staff related to ongoing SERA projects. We hope
all of you explore the website to learn more about SERA, the team behind SERA,
and our SERA research partners. Please check back periodically as we provide
updates. For our research partners, please be on the lookout for an email over
the next few weeks which will contain your login credentials, as well as
provide additional information on navigating pilot study resources and
materials.
Currently, we are in the process of preparing to conduct a
crowdsourced randomized control trial that conceptually replicates Scruggs
et al.’s (1994) study of acquisition of science facts. We will be examining
the effect of instructor-provided elaborations and student-generated
elaborations on science-fact acquisition for elementary students with
high-functioning autism across more than 20 research partners and sites
throughout the US.
We couldn’t be more excited about SERA, this website, and our upcoming pilot study. We plan on developing and refining SERA for future use in many different crowdsourced studies in special education. If you’re interested in potentially being involved in future studies, please send us a message using the contact form here. We hope that you’ll find the site interesting and helpful, and that (if you’re a special education researchers) you’ll consider being involved in a crowdsourced SERA study.